我有幸参加了一场主题为“大数据与人工智能前沿技术与应用”的专题讲座,并结合在CSDN等平台上的持续学习与交流,对人工智能基础软件开发的现状与路径有了更为系统性的思考。现将心得体会整理如下,以期与同行共勉。
一、 数据为基,智能为魂:对大数据与人工智能关系的再认识
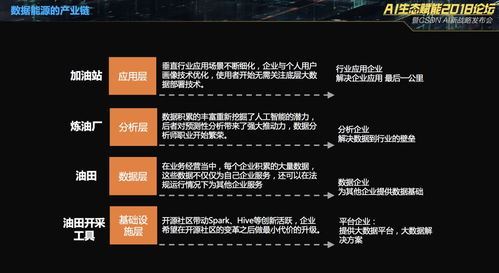
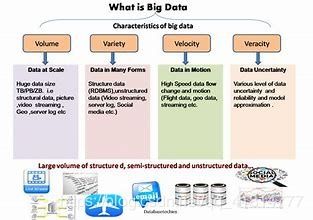
讲座开篇即深刻阐释了大数据与人工智能之间互为依托、共生共荣的关系。大数据提供了海量、多样、高速的信息原料,而人工智能则提供了从这些数据中提取知识、形成智能的算法与模型。二者结合,正驱动着从感知智能到认知智能的飞跃。这让我意识到,在当今时代,脱离高质量数据谈AI无异于“无米之炊”,而缺乏先进AI模型的数据则如同“深埋的金矿”,价值难以释放。在基础软件开发中,构建高效、可靠的数据流水线(Data Pipeline)与特征工程平台,已成为支撑AI模型训练与迭代的必备基础设施。
二、 洞见与启发:来自前沿讲座的核心观点
本次讲座的专家分享了几点关键洞见,令我印象深刻:
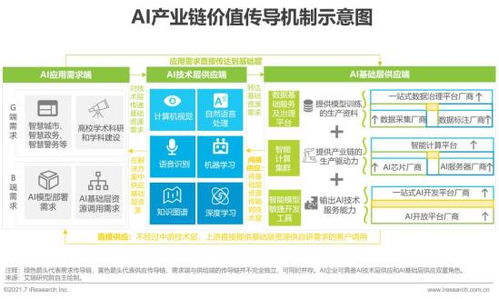
- 趋势融合化:AI不再是一个孤立的领域,而是与云计算、物联网、边缘计算深度融合。AI基础软件需要具备云边端协同、弹性伸缩的能力。
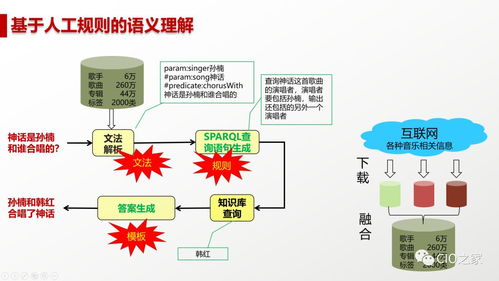
- 工程化挑战:AI模型的实验室精度与工业场景下的稳定、高效运行之间存在巨大鸿沟。讲座强调了MLOps(机器学习运维)和AIOps(智能运维)的重要性,即通过标准化、自动化的流程,管理AI模型的全生命周期,确保其可重复、可追溯、可监控。
- 开源生态驱动:以TensorFlow、PyTorch、MindSpore等为代表的深度学习框架,以及众多数据处理、模型服务工具,构成了繁荣的开源生态。这是AI基础软件开发者必须融入和贡献的沃土。
三、 知行合一:对人工智能基础软件开发的实践思考
结合讲座心得与在CSDN社区的交流学习,我对投身AI基础软件开发有了更清晰的路径认识:
- 夯实核心基础:这不仅是掌握Python、C++等编程语言,更要深入理解数据结构、算法、操作系统、计算机网络等计算机科学根基。线性代数、概率论、优化理论等数学知识是理解AI模型本质的钥匙。
- 深入主流框架与工具链:选择一个主流深度学习框架(如PyTorch,以其动态图灵活性和研究友好性备受青睐)进行深入钻研。不仅要会调用API,更要尝试理解其自动微分、计算图构建、分布式训练等核心机制。熟悉像Docker、Kubernetes这样的容器化与编排工具,以及Airflow、Kubeflow等流水线管理工具,对于构建企业级AI平台至关重要。
- 聚焦全流程能力:AI基础软件开发远不止于模型构建。一个合格的开发者或团队需要关注并实践以下环节:
- 数据管理与处理:使用Spark、Flink等处理大规模数据,利用特征存储(Feature Store)管理特征一致性。
- 模型开发与训练:掌握模型设计、调参、分布式训练优化技巧。
- 模型部署与服务化:学习如何将模型封装为API服务(如使用FastAPI、TensorFlow Serving),并考虑模型压缩、量化以适配边缘设备。
- 监控与持续迭代:建立模型性能、数据漂移的监控体系,实现模型的自动化重训练与发布。
- 拥抱社区与持续学习:CSDN、GitHub、Papers With Code等平台是宝贵的知识库和灵感来源。积极参与开源项目,阅读优秀代码,关注顶级会议(如NeurIPS, ICML, CVPR)的最新论文,是保持技术敏感度和前沿性的不二法门。
四、
此次讲座如同一座灯塔,照亮了大数据与人工智能浩瀚海洋中的关键航道。它让我深刻认识到,AI基础软件开发是一项兼具深度与广度的系统工程,需要坚实的理论底座、精湛的工程技艺和开放的生态视野。作为一名开发者,我们既是这场智能变革的使用者,更应立志成为工具与平台的塑造者。路漫漫其修远兮,唯有持续学习、深入实践、积极分享,方能在智能时代的浪潮中,贡献自己的一份代码,解决真实世界的问题。我将在夯实自身技术栈的更注重系统思维和工程能力的培养,努力向一名合格的AI基础软件工程师迈进。